What is System Design and Why is it Critical?
System design is the process of making conscious architectural decisions: how to divide responsibilities, how to ensure performance and availability, and how the system will behave under failure conditions or high traffic. Good design is a compromise between business requirements, costs, and technical complexity.
Why is System Design Critical?
1. Scalability
It allows you to plan how your application will handle growth in users or requests. Key decisions include: vertical vs horizontal scaling, sharding, and data partitioning.
2. Availability and Fault Tolerance
Designing redundancy, replication, and failover strategies (failover, retries, circuit breakers) minimizes downtime and data loss.
3. Performance (Latency)
Choosing the right caching strategy, query optimization, indexing, and appropriate patterns (like CQRS) directly impact user experience.
4. Cost Optimization
Conscious decisions about when to use cache, which replicas to maintain, and when to implement CDN can significantly reduce infrastructure costs.
5. Maintenance and Development
Clear component boundaries and stable APIs facilitate team collaboration and onboarding of new developers.
6. Security and Compliance
When designing a system, you must consider where and how sensitive data is stored and who has access to it.
Core Principles of Good System Design
- Separation of Concerns — divide responsibilities between components
- Idempotency — design operations that can be called multiple times without unwanted side effects
- Non-functional requirements first — SLA, RPS, p99/p95, RTO/RPO
- Simple and stable contracts (APIs) — facilitate component replacement
- Observability — logs, metrics, tracing from the first versions
- YAGNI (You Aren't Gonna Need It) — don't introduce complexity until it's necessary
Popular Components and Patterns (Overview)
- API Gateway / Backend — entry point; can handle auth, rate limiting, and routing
- Cache (Redis/Memcached) — reduces latency and database load
- Database (RDBMS / NoSQL) — choice depends on consistency, schema, and query patterns
- Message Queue (Kafka/RabbitMQ) — for asynchronous tasks and integration
- CDN — serves static assets closer to users
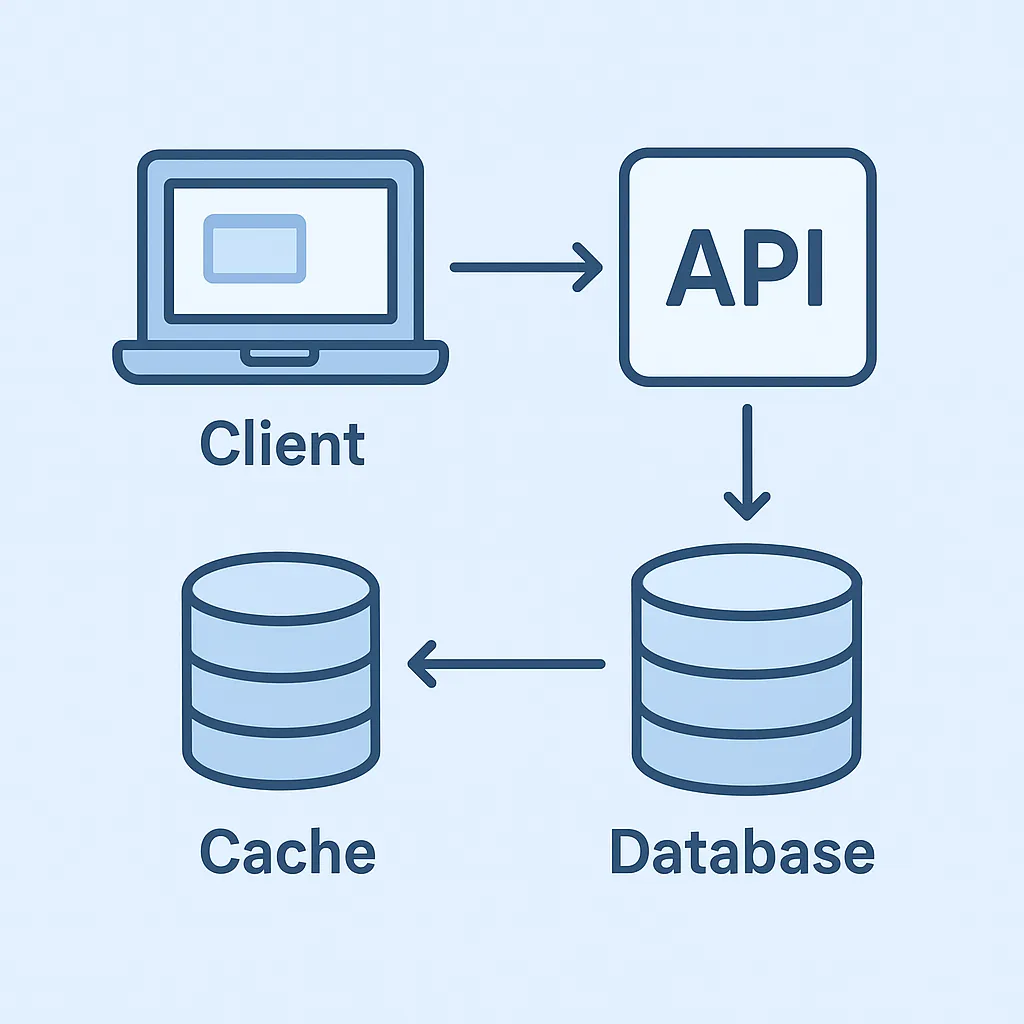
Simple Architecture Diagram: API + Cache + DB
ASCII Diagram
[Client] --HTTP--> [API / Backend]
|
v
[Cache (Redis)]
|
on miss -> v
[Database (PostgreSQL)]
Flow Description:
- Client sends a request to the API
- API attempts to retrieve data from cache (fast reads)
- if cache hit → returns data immediately
- if cache miss → API reads from DB, stores result in cache, and returns response
- On writes, API saves to DB and invalidates or updates cache (cache-aside or other pattern)
Example: Cache-Aside Pattern (Pseudocode)
def get_user(user_id):
key = f"user:{user_id}"
user = cache.get(key)
if user:
return user # cache hit
# cache miss -> read from DB
user = db.query("SELECT * FROM users WHERE id = %s", user_id)
if user:
cache.set(key, user, ttl=300) # cache for 5 minutes
return user
def update_user(user_id, new_data):
db.update_user(user_id, new_data)
cache.delete(f"user:{user_id}") # cache invalidation
Notes: Cache-aside is simple and popular, but requires thoughtful TTL and invalidation strategies to avoid stale data.
Common Pitfalls and How to Avoid Them
- Lack of cache invalidation strategy → stale data
- Premature microservices fragmentation → operational complexity
- Missing rate limiting → vulnerability to DoS attacks
- Careless distributed transactions → data consistency issues
- Lack of load testing → unexpected production failures